
Google veröffentlicht ARD-Spezifikation? Dieser strategische Schritt wurde schlüssig bestätigt, da sich bedeutende Technologieakteure auf ein einheitliches Protokoll einigen, um das Dilemma des plattformübergreifenden Tool-Routings zu lösen. Am 17. Juni 2026 hat Google Cloud offiziell die Open-Source-Spezifikation vorgestellt. Die Marktdynamik rund um diese Einführung der Google ARD-Spezifikation zeigt, dass sich die Entwickler-Community auf ein föderiertes, domain-validiertes Netzwerk zubewegt. Dieses System stellt einen bedeutenden Wandel von zentraler Store-Indexierung hin zu dezentraler, domain-validierter Discovery dar, wodurch der Verlust kritischer Parameter verhindert wird, wenn autonome Agenten Workflows über Netzwerkgrenzen hinweg steuern.
Fragmentierung des föderierten Webs: Die Google ARD-Spezifikation
Ankündigung der offenen Spezifikation für Resource Discovery
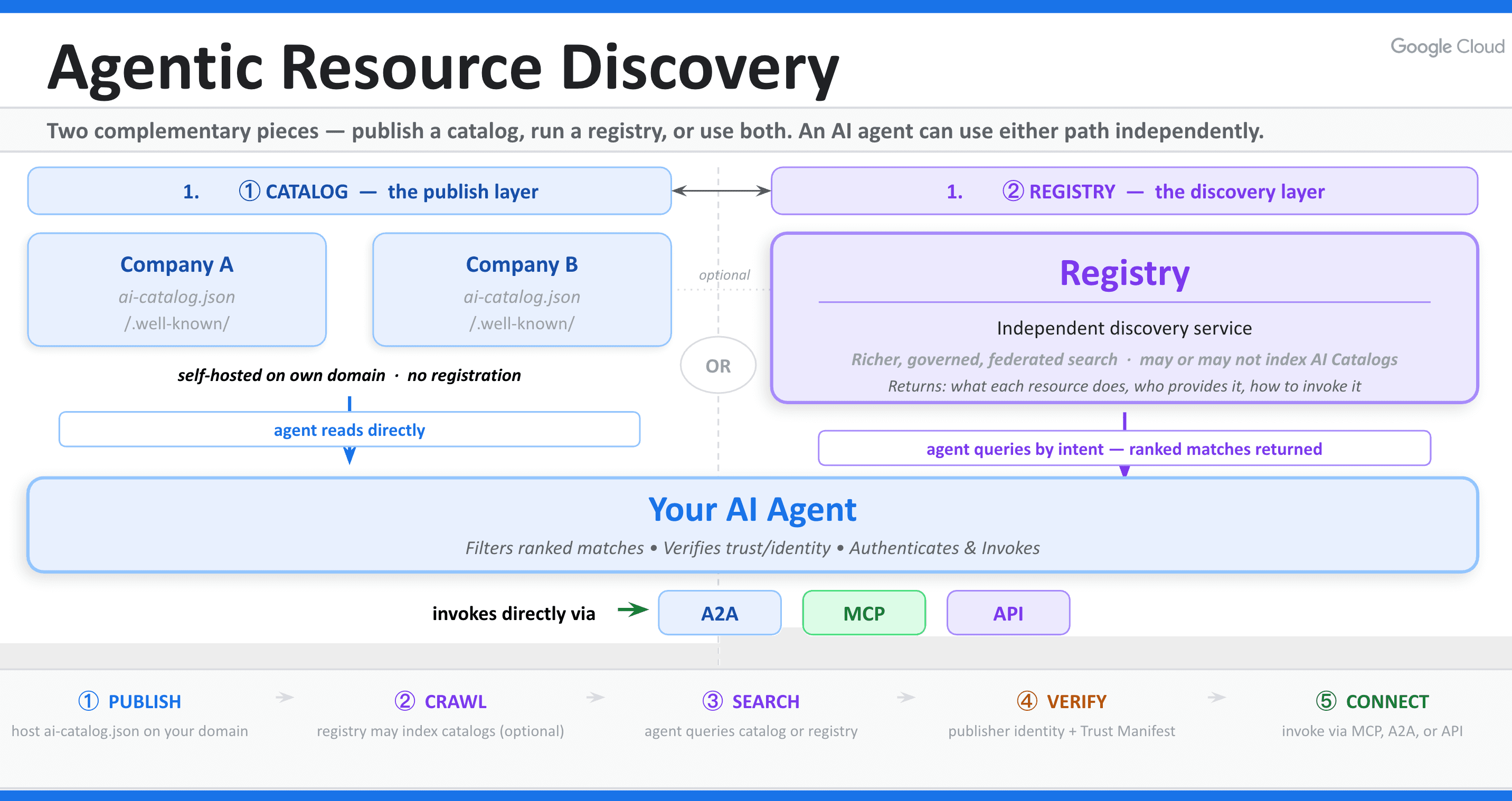
Die Software-Ingenieure Junjie Bu und Srinivas Krishnan von Google Cloud haben die Agentic Resource Discovery (ARD)-Spezifikation unter der Apache 2.0-Lizenz eingeführt. Entscheidend ist, dass das Protokoll direkt auf dem grundlegenden KI-Katalog-Datenmodell aufbaut, das von der AI Catalog Working Group unter der Linux Foundation entwickelt wurde.
Dieses offene Framework adressiert konkret einen wesentlichen operativen Engpass im agentenbasierten Computing. KI-Agenten bleiben derzeit fragmentiert und in spezifischen, benutzerdefinierten Registries isoliert.
Folglich hat ein Agent, der in einer Umgebung arbeitet, keine standardisierte Möglichkeit, Fähigkeiten zu lokalisieren oder zu verifizieren, die anderswo gehostet werden. ARD bietet diese fehlende Ebene. Es standardisiert, wie Unternehmen verfügbare Tools, Fähigkeiten und Agenten direkt unter ihrem eigenen Domainnamen veröffentlichen, wodurch sie über föderierte Registries hinweg durchsuchbar werden.
Dekonstruktion des ai-catalog.json-Schemas und der Payloads
Im Zentrum des Standards liegt das Manifest ai-catalog.json. Dieses Manifest enthält detaillierte, strukturierte Metadaten, die die verfügbaren Fähigkeiten des Anbieters beschreiben.
Um einen Katalog zu veröffentlichen, hostet eine Organisation diese JSON-Datei unter einem bekannten Pfad auf ihrer eigenen Domain. Da die Datei direkt unter dem Domainnamen der Organisation liegt, dient der Domänenbesitz als kryptografisches Fundament für die Identität.
Das Katalog-Payload kann verschiedene Tool-Klassen beschreiben, darunter Model Context Protocol (MCP)-Server, OpenAPI-Tools oder sogar verschachtelte Unterkataloge. Diese flexible Struktur ermöglicht es Agenten, verfügbare Ressourcen programmgesteuert zu parsen, was das Vorladen umfangreicher, ungenutzter Bibliotheken überflüssig macht.
Föderierte Registries: Crawling und Indexierung des agentenbasierten Webs
Während Kataloge die Metadaten speichern, fungieren Registries als Suchmaschinen für das agentenbasierte Web. Konkret crawlen diese Registries veröffentlichte Kataloge und indexieren deren Inhalte.
Wenn ein Agent eine spezifische Fähigkeit benötigt, übermittelt er eine Discovery-Anfrage in natürlicher Sprache an die Registry. Die Registry liefert daraufhin die passenden Tools zusammen mit den kryptografischen Vertrauens-Metadaten zurück.
Die Registry übernimmt dabei ausschließlich die Discovery-Phase. Sobald der Handshake abgeschlossen ist, tritt sie in den Hintergrund, wodurch der Agent eine direkte Verbindung zum Endpunkt des Tools herstellen kann. Dieses dezentrale Föderationsmodell verhindert, dass ein einzelner Anbieter ein Discovery-Monopol über das agentenbasierte Web errichtet.
Google Cloud-Integration: Agent Registry in der Gemini-Plattform
Google Cloud unterstützt diese offene Spezifikation durch eine native Produktintegration. Das Unternehmen führte die Agent Registry in der Gemini Enterprise Agent Platform ein.
Dieses System für Unternehmen bietet vollständig gehosteten Support für das Suchen, Entdecken und Hosten von agentenbasierten Ressourcen. Die Agent Registry verwaltet sichere Ressourcen mittels Agent Identity, um das Vertrauensmanifest vor der Ausführung zu verifizieren.
Diese Verifizierungsebene erzwingt strikte Agenten-Egress-Richtlinien und weist global eindeutige, namensraumbezogene URNs zu. Dies hilft Unternehmenskunden dabei, strenge Compliance-Standards wie HIPAA einzuhalten und sicherzustellen, dass autonome Handshakes vollständig authentifiziert und vor Abhörversuchen geschützt bleiben.
GitHub Copilot-Integration: Einführung des Agent Finders
Microsoft schloss sich dem föderierten Netzwerk durch die Einführung des Agent Finders für GitHub Copilot an. Historisch gesehen mussten Entwickler MCP-Server manuell konfigurieren und injizieren, was oft das LLM-Kontextfenster füllte.
Der neue Agent Finder behebt diese Einschränkung. Durch die Implementierung der offenen Spezifikation kann Copilot nun einen Index verfügbarer KI-Ressourcen durchsuchen.
Infolgedessen lädt das System Tools dynamisch basierend auf den Anforderungen der Aufgabe in natürlicher Sprache. Da das System den offenen Standard nutzt, können Entwickler den Agent Finder auf GitHubs kuratierten öffentlichen Katalog oder ihre eigenen privaten, sicheren internen Registries verweisen.
![]()
Umgehung des App-Funnels bei autonomen Transaktionen
Umgehung der manuellen visuellen Schnittstelle
Da Entwicklungsteams durch schnelle Codegenerierung Tausende kleiner Anwendungen bereitstellen, sieht sich das mobile Web einer beispiellosen Flut an Produkten gegenüber. Dieser massive Zuwachs an Softwarevolumen geht jedoch mit einem vollständigen Verschwinden der traditionellen Benutzeroberfläche einher.
Wenn ein autonomer Agent den offenen Standard nutzt, um eine Aufgabe zu erfüllen, entfällt die menschliche visuelle Reise. Der Agent fragt direkt indexierte Kataloge ab und führt das erforderliche Tool im Hintergrund aus.
Folglich beobachten wir einen massiven Wandel von aktivem Web-Traffic hin zu absichtsbasiertem Traffic. Menschen durchsuchen keine Landingpages mehr und klicken nicht auf Werbe-Redirects aus App Stores. Stattdessen treffen Softwareprozesse im Hintergrund Routing-Entscheidungen, was traditionelle Werbekanäle ineffektiv macht.
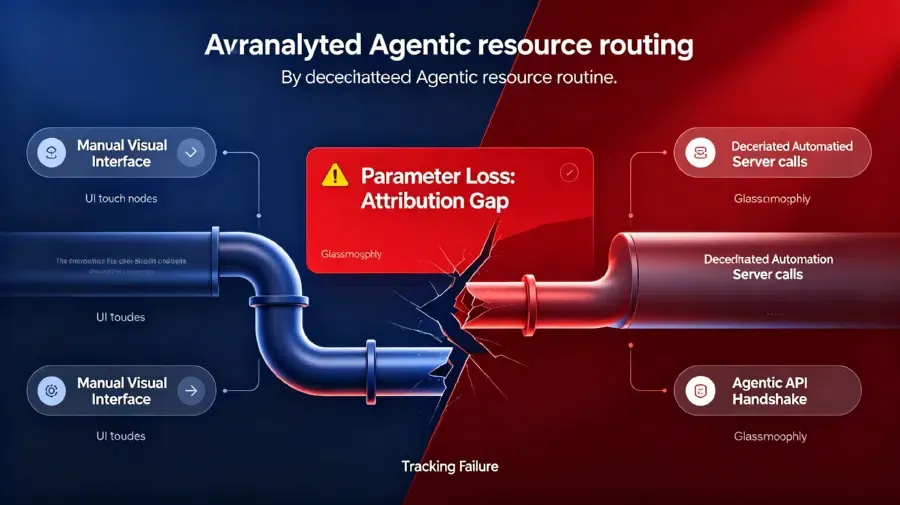
Die Herausforderung des Parameterverlusts bei der agentenbasierten Discovery
Traditionelles App-Routing basiert auf Cookies und URL-Weiterleitungen, um die User Journey abzubilden. Wenn ein Agent die Tool-Discovery automatisiert, werden diese Weiterleitungsmechanismen eliminiert.
Der Agent etabliert einen direkten API-Handshake. Infolgedessen gehen entscheidende Referral-Parameter und Marketing-Attributions-Tags während der Übertragung verloren.
Mobile Measurement-Plattformen erhalten leere Metadaten-Pakete. Entwickler verlieren dadurch die Fähigkeit, den Ursprung des Verkaufs nachzuverfolgen, was eine massive Datenlücke schafft.
Referenzarchitekturen & Engineering-Referenzen
Wiederaufbau des Parameter-Handshakes
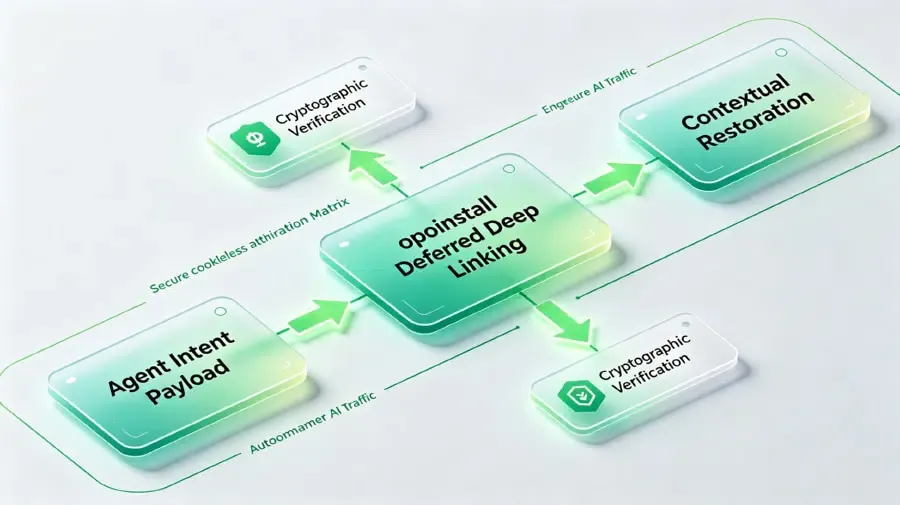
Um diese Lücke im semantischen Routing zu schließen, müssen Softwarearchitekten sichere Frameworks zur Parametererhaltung einsetzen. Wenn ein externer Agent eine Anwendung aufruft, muss er ein verifiziertes Payload übertragen, das die ursprüngliche Absicht des Benutzers, Referral-Parameter und Sicherheitstoken enthält.
Entwickler können eine robuste Lösung mithilfe des Deferred Deep Linking-Frameworks etablieren. Dieses System stellt sicher, dass dynamische Payload-Parameter Hintergrund-Installationsschleifen überdauern. Selbst wenn das Gerät die native Anwendung nicht besitzt, bewahrt die Infrastruktur zur kontextuellen Wiederherstellung das Intent-Payload und übergibt es beim ersten Start sicher an die App.
{
"applinks": {
"apps": [],
"details": [
{
"appID": "9H938Y49U3.com.opoinstall.global",
"paths": [ "/intent/*", "/restore/*" ]
}
]
}
}
Kryptografische Verifizierung für Machine-to-Machine-Transaktionen
Zusätzlich erfordert die Sicherung dieser automatisierten Transaktionen strikte kryptografische Handshakes. Da Hintergrundagenten ohne visuelle menschliche Aufsicht agieren, können bösartige Skripte versuchen, Transaktionsanfragen zu fälschen.
Um dies zu verhindern, muss jede Deep-Link-Routing-Anfrage eine verifizierbare kryptografische Signatur enthalten. Die Anwendung muss diese Signatur vor der Ausführung einer Aktion gegen öffentliche Entwickler-Registries validieren.
Die Durchsetzung eines sicheren Deferred Deep Linking-Frameworks ermöglicht es Entwicklungsteams, diese Validierungen automatisch durchzuführen. Dieser Prozess schützt die Anwendungssandbox vor betrügerischen Installationen und sichert die Transaktions-Pipeline gegen Ad-Fraud ab.
Branchenausblick: Bezüglich der geräteübergreifenden Parameterübertragung für autonomen Intent-Traffic führt das Tech-Labor von opoinstall derzeit gemeinsame explorative Forschungsarbeiten mit führenden Unternehmenspartnern durch.
Technische Sicherheitsvorgaben für Unternehmensarchitekturen
Für Entwickler und Systemarchitekten
Die Integration einer nativen Implementierung der Google ARD-Spezifikation in die Anwendungsarchitektur erfordert einen wesentlichen Wandel in den Entwicklungspraktiken. Ingenieure müssen vom Entwurf traditioneller visueller Navigationspfade zur Konstruktion detaillierter App-Intents übergehen. Diese Intents ermöglichen es systemweiten Agenten, App-Strukturen zu lesen und Daten programmgesteuert abzufragen.
Des Weiteren müssen Entwickler eine strikte Signaturprüfung implementieren, um alle eingehenden Deep-Link-Payloads zu validieren. Diese Validierung verhindert, dass schädliche Agenten aus der lokalen Sandbox ausbrechen oder betrügerische Käufe auslösen. Architekten müssen zudem einheitliche plattformübergreifende ID-Systeme konfigurieren, um die User Journey über iOS, Android und HarmonyOS NEXT hinweg nachzuverfolgen.
Für Produkt- und Growth-Manager
Unterdessen müssen Produkt- und Marketingverantwortliche ihre Wachstumsmetriken neu definieren. In einer agentenbasierten Umgebung verlieren traditionelle KPIs wie Seitenaufrufe, Absprungraten und Sitzungsdauern an Wert.
Stattdessen müssen sich Growth-Teams auf „Intent Capture Rates“ optimieren. Sie müssen sicherstellen, dass ihre Anwendung hochstrukturierte, maschinenlesbare Metadaten bereitstellt, die Agenten leicht parsen können.
Darüber hinaus müssen Teams fortschrittliche Anti-Fraud-Filter einsetzen, um automatisierte, skriptbasierte Downloads zu identifizieren und zu blockieren. Dieser Schutz stellt sicher, dass Akquisitionsbudgets für echtes Nutzerwachstum ausgegeben werden und nicht für aufgeblähten, maschinengenerierten Traffic.
Häufig gestellte Fragen (FAQ)
Letztendlich steht die traditionelle, klickbasierte Wirtschaft vor einem raschen Niedergang. Während Zahlungsnetzwerke und Betriebssysteme zu autonomen, agentenbasierten Architekturen übergehen, verlagert sich der Wert von Software auf die darunterliegende Routing-Ebene.
Folglich ist der Aufbau robuster, parameter-sicherer Deep-Linking-Backbones kein Luxus mehr. Es ist eine grundlegende operative Anforderung. Indem Sie Ihre Anwendungsarchitektur heute auf die agentenbasierte Wirtschaft vorbereiten, stellen Sie sicher, dass Ihre Software auch in der Post-Screen-Ära zugänglich, verifiziert und profitabel bleibt.
Share this article



