
¿Google lanza la especificación ARD? Este giro estratégico ha sido validado de forma concluyente a medida que los principales actores tecnológicos se alinean bajo un protocolo unificado para resolver el dilema del enrutamiento de herramientas multiplataforma. El 17 de junio de 2026, Google Cloud presentó oficialmente la especificación de código abierto. El impulso del mercado en torno a este despliegue de la especificación ARD de Google demuestra que la comunidad de desarrolladores se dirige hacia una red federada y validada por dominio. Este sistema representa un cambio importante desde la indexación centralizada de tiendas hacia un descubrimiento descentralizado validado por dominio, evitando la pérdida de parámetros críticos a medida que los agentes autónomos enrutan los flujos de trabajo a través de los límites de la red.
Fragmentación de la web federada: el lanzamiento de la especificación ARD de Google
Anuncio de la especificación abierta para el descubrimiento de recursos
Los ingenieros de software de Google Cloud, Junjie Bu y Srinivas Krishnan, introdujeron la especificación de Descubrimiento de Recursos por Agentes (ARD, por sus siglas en inglés) bajo la licencia Apache 2.0. Fundamentalmente, el protocolo se basa directamente en el modelo de datos del catálogo de IA desarrollado por el Grupo de Trabajo de Catálogos de IA bajo la Linux Foundation.
Específicamente, este marco abierto aborda un cuello de botella operativo importante en la computación por agentes. Actualmente, los agentes de IA permanecen fragmentados y aislados dentro de registros personalizados específicos.
En consecuencia, un agente que trabaja en un entorno no tiene una forma estándar de localizar o verificar capacidades alojadas en otro lugar. ARD proporciona esa capa faltante. Estandariza la forma en que las organizaciones publican sus herramientas, habilidades y agentes disponibles directamente bajo su propio nombre de dominio, haciéndolos buscables a través de registros federados.
Deconstrucción del esquema y la carga útil de ai-catalog.json
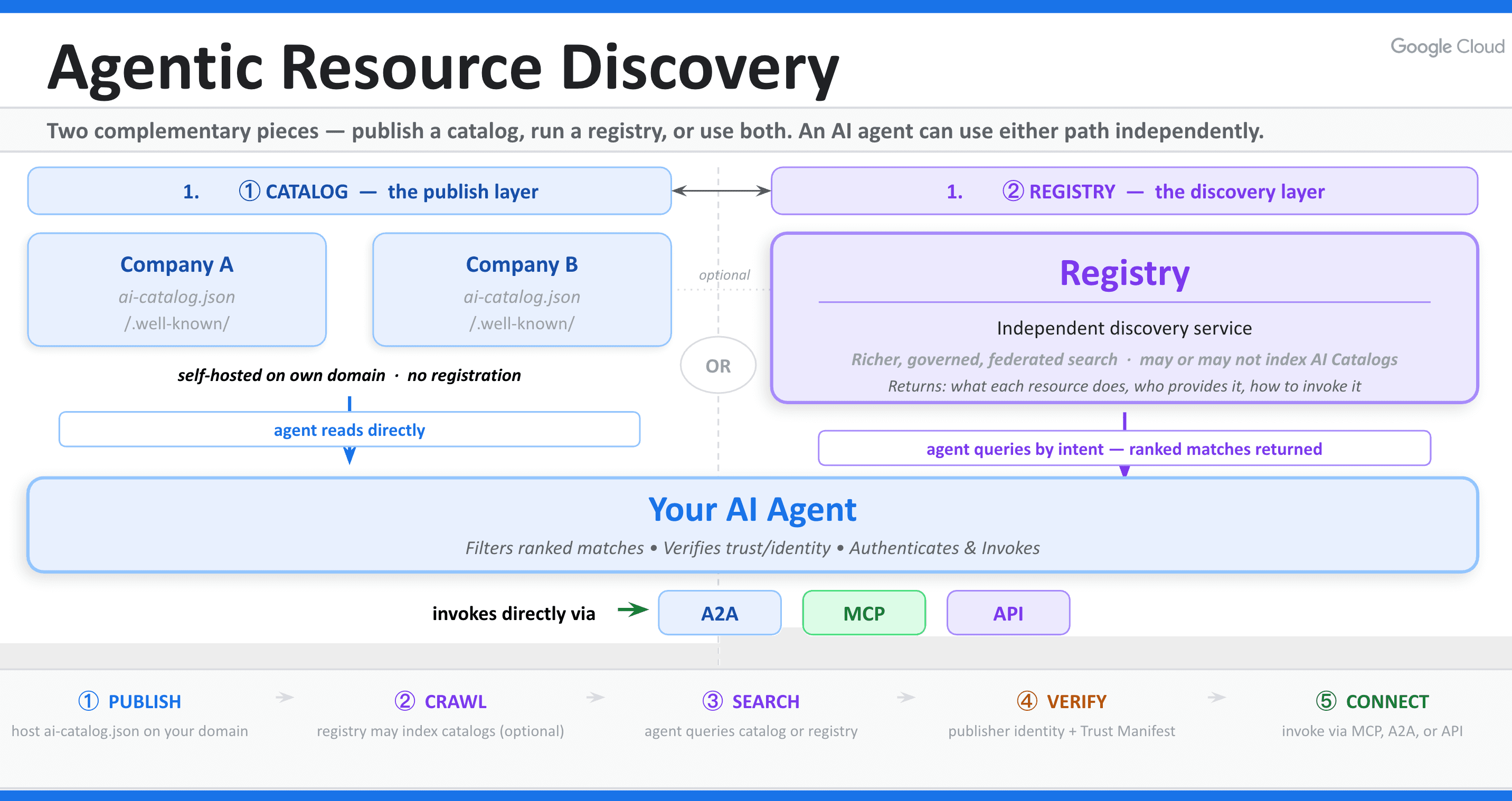
En el corazón del estándar se encuentra el manifiesto ai-catalog.json. Específicamente, este manifiesto contiene metadatos altamente estructurados que describen las capacidades disponibles del proveedor.
Para publicar un catálogo, una organización aloja este archivo JSON en una ruta conocida dentro de su propio dominio. Dado que el archivo reside directamente bajo el nombre de dominio de la organización, la propiedad del dominio sirve como base criptográfica para la identidad.
La carga útil del catálogo puede describir múltiples clases de herramientas, incluidos servidores del Protocolo de Contexto de Modelo (MCP), herramientas de OpenAPI o incluso subcatálogos anidados. Esta estructura de carga útil flexible permite a los agentes analizar los recursos disponibles mediante programación, eliminando la necesidad de precargar bibliotecas pesadas y no utilizadas.
Registros federados: rastreo e indexación de la web de agentes
Mientras que los catálogos almacenan los metadatos, los registros actúan como motores de búsqueda para la web de agentes. Específicamente, los registros rastrean los catálogos publicados e indexan sus contenidos.
Cuando un agente necesita una capacidad específica, envía una solicitud de descubrimiento en lenguaje natural al registro. El registro devuelve las herramientas coincidentes junto con los metadatos de confianza criptográfica.
Fundamentalmente, el registro solo maneja la fase de descubrimiento. Una vez completado el intercambio, el registro se retira, permitiendo que el agente se conecte directamente al punto final de la herramienta. Este modelo de federación descentralizada evita que cualquier proveedor establezca un monopolio de descubrimiento sobre la web de agentes.
Integración de Google Cloud: Registro de Agentes en la plataforma Gemini
Google Cloud respalda esta especificación abierta con una integración nativa en su producto. Específicamente, la compañía introdujo el Registro de Agentes en la Plataforma de Agentes Empresariales Gemini.
Este sistema de nivel empresarial proporciona soporte totalmente alojado para buscar, descubrir y alojar recursos de agentes. Fundamentalmente, el Registro de Agentes gestiona recursos seguros utilizando la Identidad del Agente para verificar el manifiesto de confianza antes de la ejecución.
Esta capa de verificación aplica políticas estrictas de egreso de agentes y asigna URNs (nombres de recursos uniformes) con espacios de nombres únicos a nivel mundial. En consecuencia, ayuda a los clientes empresariales a cumplir con estándares de cumplimiento estrictos como HIPAA, garantizando que los intercambios autónomos permanezcan completamente autenticados y protegidos contra interceptaciones.
Integración de GitHub Copilot: Lanzamiento del Buscador de Agentes
Microsoft también se ha unido a la red federada mediante el lanzamiento del Buscador de Agentes para GitHub Copilot. Históricamente, los desarrolladores tenían que configurar e inyectar manualmente servidores MCP, lo que a menudo llenaba la ventana de contexto de los modelos de lenguaje (LLM).
El nuevo Buscador de Agentes resuelve esta limitación. Al implementar la especificación abierta, Copilot ahora puede buscar en un índice de recursos de IA disponibles.
En consecuencia, carga las herramientas dinámicamente según los requisitos en lenguaje natural de la tarea. Debido a que el sistema utiliza el estándar abierto, los desarrolladores pueden dirigir el Buscador de Agentes al catálogo público curado de GitHub o a sus propios registros internos privados y seguros.
![]()
Omisión del embudo de aplicaciones en transacciones autónomas
Omisión de la interfaz visual manual
A medida que los equipos de desarrollo utilizan la generación rápida de código para desplegar miles de aplicaciones menores, la web móvil se enfrenta a una inundación de productos sin precedentes. Sin embargo, este aumento masivo en el volumen de software coincide con una evaporación total de la interfaz de usuario tradicional.
Cuando un agente autónomo utiliza el estándar abierto para completar una tarea, el viaje visual del usuario desaparece. El agente consulta directamente los catálogos indexados y ejecuta la herramienta requerida en segundo plano.
En consecuencia, observamos un cambio masivo del tráfico web activo al tráfico impulsado por la intención. Los humanos ya no navegan por páginas de destino ni hacen clic en redirecciones promocionales de la tienda. En cambio, los procesos de software en segundo plano toman decisiones de enrutamiento, lo que hace que los canales de publicidad tradicionales sean ineficaces.
El desafío de la pérdida de parámetros en el descubrimiento por agentes
El enrutamiento tradicional de aplicaciones depende de cookies y redirecciones de URL para mapear el viaje del usuario. Cuando un agente automatiza el descubrimiento de herramientas, estos mecanismos de redirección se eliminan.
El agente establece un intercambio de API directo. Como resultado, los parámetros de referencia críticos y las etiquetas de atribución de marketing se eliminan durante el tránsito.
Las plataformas de medición móvil reciben paquetes de metadatos vacíos. En consecuencia, los desarrolladores pierden la capacidad de rastrear el origen de la venta, creando una brecha de datos masiva.
Arquitecturas de referencia y referencias de ingeniería
Reconstrucción del intercambio de parámetros
Para cerrar esta brecha de enrutamiento semántico, los arquitectos de software deben desplegar marcos de trabajo de preservación de parámetros seguros. Cuando un agente externo invoca una aplicación, debe transmitir una carga útil verificada que contenga la intención original del usuario, los parámetros de referencia y los tokens de seguridad.
Fundamentalmente, los desarrolladores pueden establecer una solución resiliente utilizando el marco de trabajo de Deferred Deep Linking. Este sistema asegura que los parámetros de carga útil dinámicos sobrevivan a los ciclos de instalación en segundo plano. Incluso si el dispositivo carece de la aplicación nativa, la infraestructura de restauración contextual preserva la carga útil de intención, pasándola de forma segura a la aplicación en el primer lanzamiento.
{
"applinks": {
"apps": [],
"details": [
{
"appID": "9H938Y49U3.com.opoinstall.global",
"paths": [ "/intent/*", "/restore/*" ]
}
]
}
}
Verificación criptográfica para transacciones máquina a máquina
Además, asegurar estas transacciones automatizadas requiere intercambios criptográficos estrictos. Debido a que los agentes en segundo plano operan sin supervisión humana visual, los scripts maliciosos pueden intentar falsificar solicitudes de transacción.
Para evitar esto, cada solicitud de enrutamiento de deep link debe llevar una firma criptográfica verificable. La aplicación debe validar esta firma contra los registros de desarrolladores públicos antes de ejecutar cualquier acción.
La aplicación de un marco de trabajo de Deferred Deep Linking seguro permite a los equipos de desarrollo ejecutar estas validaciones automáticamente. Este proceso protege el sandbox de la aplicación de instalaciones fraudulentas y asegura la tubería de transacciones contra el fraude publicitario.
Nota de perspectiva de la industria: Con respecto al paso de parámetros entre dispositivos para el tráfico de intención autónomo, el laboratorio técnico de opoinstall está realizando actualmente investigaciones exploratorias conjuntas con socios líderes de aplicaciones empresariales.
Mandatos de seguridad técnica para arquitecturas empresariales
Para desarrolladores y arquitectos de sistemas
Integrar una implementación nativa de la especificación ARD de Google en la arquitectura de la aplicación requiere un cambio importante en las prácticas de desarrollo. Los ingenieros deben pasar del diseño de rutas de navegación visual tradicionales a la construcción de Intents de Aplicación detallados. Estos intents permiten a los agentes a nivel de sistema leer estructuras de aplicaciones y consultar datos mediante programación.
Además, los desarrolladores deben implementar una verificación de firma estricta para validar todas las cargas útiles de deep links entrantes. Esta validación evita que agentes malintencionados ejecuten escapes de sandbox locales o activen compras fraudulentas. Los arquitectos también deben configurar sistemas de identificación multiplataforma unificados para rastrear el viaje del usuario a través de iOS, Android y HarmonyOS NEXT.
Para gerentes de producto y crecimiento
Mientras tanto, los responsables de producto y marketing deben redefinir sus métricas de crecimiento. En un entorno de agentes, las métricas tradicionales de KPI como las visitas a páginas, las tasas de rebote y la duración de las sesiones pierden su valor.
En cambio, los líderes de crecimiento deben optimizar las "Tasas de captura de intención". Deben asegurarse de que su aplicación proporcione metadatos altamente estructurados y legibles por máquina que los agentes puedan analizar fácilmente.
Además, los equipos deben desplegar filtros avanzados antifraude para identificar y bloquear las descargas automatizadas basadas en scripts. Esta protección garantiza que los presupuestos de adquisición se gasten en el crecimiento real de usuarios en lugar de en tráfico inflado generado por máquinas.
Preguntas frecuentes (FAQ)
En última instancia, la economía tradicional basada en clics se enfrenta a un rápido declive. A medida que las redes de pago y los sistemas operativos de los dispositivos transicionan hacia arquitecturas de agentes autónomos, el valor del software se está desplazando hacia la capa de enrutamiento subyacente.
En consecuencia, construir backbones de deep linking robustos y con parámetros seguros ya no es un lujo. Es un requisito operativo fundamental. Al preparar la arquitectura de su aplicación para la economía de agentes hoy, usted garantiza que su software siga siendo accesible, verificado y rentable en la era posterior a la pantalla.
Share this article


