
Google publie la spécification ARD ? Ce virage stratégique a été validé de manière concluante alors que les principaux acteurs technologiques s'alignent sur un protocole unifié pour résoudre le dilemme du routage d'outils multiplateformes. Le 17 juin 2026, Google Cloud a officiellement lancé la spécification open source. La dynamique du marché entourant ce déploiement de la spécification ARD de Google démontre que la communauté des développeurs s'oriente vers un réseau fédéré et validé par domaine. Ce système représente un changement majeur, passant de l'indexation centralisée des stores à une découverte décentralisée et validée par domaine, évitant ainsi la perte de paramètres critiques lorsque des agents autonomes dirigent les flux de travail à travers les limites du réseau.
Fragmentation du Web fédéré : La publication de la spécification ARD de Google
Annonce de la spécification ouverte pour la découverte de ressources
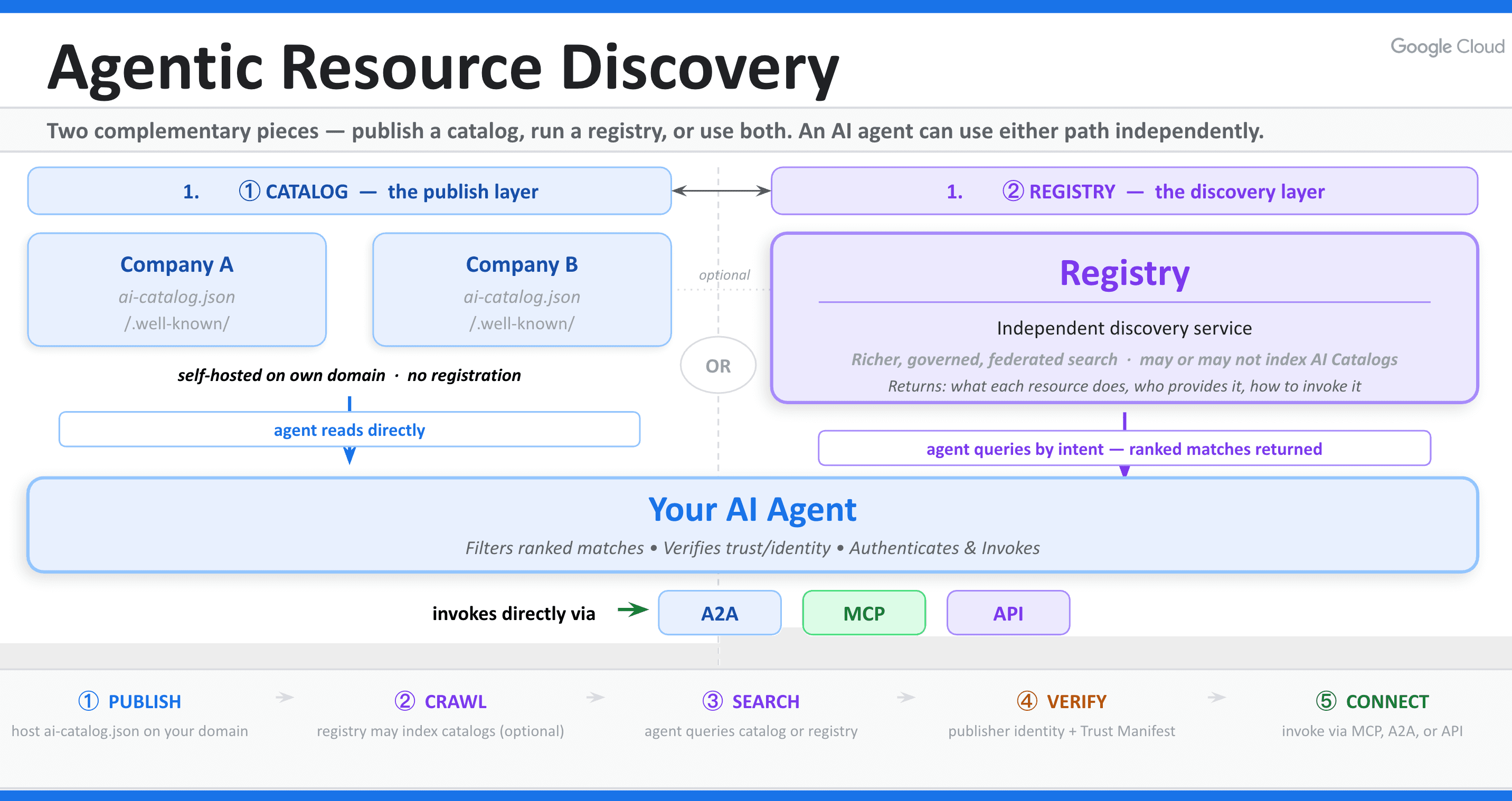
Les ingénieurs logiciels de Google Cloud, Junjie Bu et Srinivas Krishnan, ont introduit la spécification Agentic Resource Discovery (ARD) sous licence Apache 2.0. Il est crucial de noter que le protocole s'appuie directement sur le modèle de données AI Catalog développé par l'AI Catalog Working Group sous l'égide de la Linux Foundation.
Plus précisément, ce cadre ouvert répond à un goulot d'étranglement opérationnel majeur dans l'informatique agentique. Les agents IA restent actuellement fragmentés et isolés au sein de registres personnalisés spécifiques.
Par conséquent, un agent travaillant dans un environnement n'a aucun moyen standard de localiser ou de vérifier les capacités hébergées ailleurs. L'ARD fournit cette couche manquante. Elle standardise la manière dont les organisations publient leurs outils, compétences et agents disponibles directement sous leur propre nom de domaine, les rendant ainsi consultables à travers des registres fédérés.
Déconstruction du schéma et de la charge utile ai-catalog.json
Au cœur de la norme se trouve le manifeste ai-catalog.json. Plus précisément, ce manifeste contient des métadonnées hautement structurées décrivant les capacités disponibles du fournisseur.
Pour publier un catalogue, une organisation héberge ce fichier JSON à un chemin bien connu sur son propre domaine. Comme le fichier réside directement sous le nom de domaine de l'organisation, la propriété du domaine sert de fondement cryptographique à l'identité.
La charge utile du catalogue peut décrire plusieurs classes d'outils, y compris des serveurs MCP (Model Context Protocol), des outils OpenAPI, ou même des sous-catalogues imbriqués. Cette structure de charge utile flexible permet aux agents d'analyser les ressources disponibles par programmation, éliminant ainsi le besoin de précharger des bibliothèques lourdes et inutilisées.
Registres fédérés : Exploration et indexation du Web agentique
Alors que les catalogues stockent les métadonnées, les registres agissent comme des moteurs de recherche pour le web agentique. Plus précisément, les registres explorent les catalogues publiés et indexent leur contenu.
Lorsqu'un agent a besoin d'une capacité spécifique, il soumet une demande de découverte en langage clair au registre. Le registre renvoie alors les outils correspondants ainsi que les métadonnées de confiance cryptographiques.
Il est essentiel de noter que le registre ne gère que la phase de découverte. Il s'efface une fois la poignée de main terminée, permettant à l'agent de se connecter directement au point de terminaison de l'outil. Ce modèle de fédération décentralisée empêche tout fournisseur unique d'établir un monopole de découverte sur le web agentique.
Intégration Google Cloud : Registre d'agents dans la plateforme Gemini
Google Cloud soutient cette spécification ouverte avec une intégration native au produit. Plus précisément, l'entreprise a introduit l'Agent Registry dans la Gemini Enterprise Agent Platform.
Ce système de qualité entreprise offre un support entièrement hébergé pour la recherche, la découverte et l'hébergement de ressources agentiques. Essentiellement, l'Agent Registry gère les ressources sécurisées en utilisant l'identité de l'agent pour vérifier le manifeste de confiance avant l'exécution.
Cette couche de vérification impose des politiques de sortie agentiques strictes et attribue des URN avec espaces de noms uniques à l'échelle mondiale. Par conséquent, elle aide les entreprises clientes à respecter des normes de conformité strictes telles que HIPAA, garantissant que les poignées de main autonomes restent entièrement authentifiées et protégées contre toute interception.
Intégration GitHub Copilot : Lancement de l'Agent Finder
Microsoft a également rejoint le réseau fédéré en lançant l'Agent Finder pour GitHub Copilot. Historiquement, les développeurs devaient configurer et injecter manuellement des serveurs MCP, ce qui remplissait souvent la fenêtre de contexte du LLM.
Le nouvel Agent Finder résout cette limitation. En implémentant la spécification ouverte, Copilot peut désormais rechercher dans un index de ressources IA disponibles.
Par conséquent, il charge les outils dynamiquement en fonction des besoins en langage clair de la tâche. Comme le système utilise la norme ouverte, les développeurs peuvent orienter l'Agent Finder vers le catalogue public organisé de GitHub ou vers leurs propres registres internes privés et sécurisés.
![]()
Contourner le tunnel d'application dans les transactions autonomes
Contourner l'interface visuelle manuelle
À mesure que les équipes de développement utilisent la génération de code rapide pour déployer des milliers d'applications mineures, le web mobile fait face à un afflux de produits sans précédent. Cependant, cette augmentation massive du volume de logiciels coïncide avec une évaporation totale de l'interface utilisateur traditionnelle.
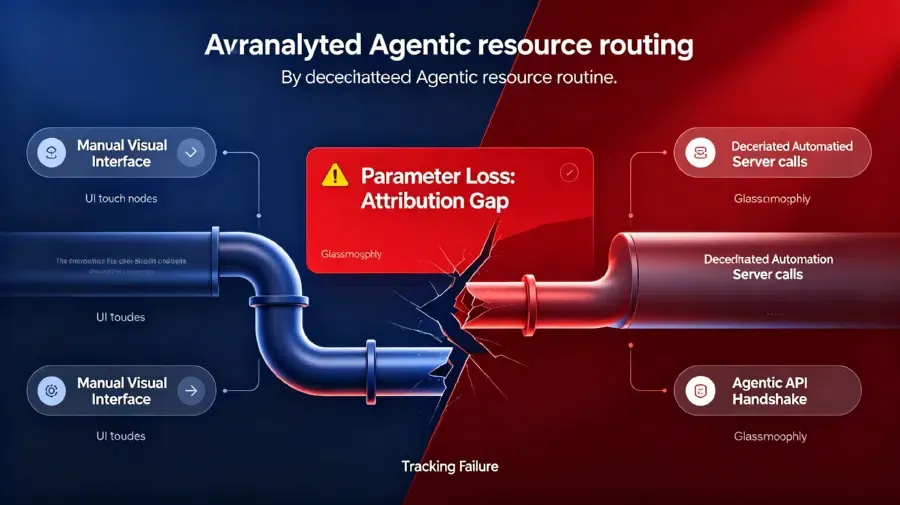
Lorsqu'un agent autonome utilise la norme ouverte pour accomplir une tâche, le parcours visuel humain disparaît. L'agent interroge directement les catalogues indexés et exécute l'outil requis en arrière-plan.
Par conséquent, nous observons un transfert massif du trafic web actif vers un trafic axé sur l'intention. Les humains ne parcourent plus les pages de destination et ne cliquent plus sur les redirections promotionnelles des stores. Au lieu de cela, les processus logiciels en arrière-plan prennent les décisions de routage, rendant les canaux marketing traditionnels inefficaces.
Le défi de la perte de paramètres dans la découverte agentique
Le routage d'applications traditionnel dépend des cookies et des redirections URL pour cartographier le parcours utilisateur. Lorsqu'un agent automatise la découverte d'outils, ces mécanismes de redirection sont éliminés.
L'agent établit une poignée de main API directe. En conséquence, les paramètres de référence critiques et les tags d'attribution marketing sont supprimés pendant le transit.
Les plateformes de mesure mobile reçoivent des paquets de métadonnées vides. Par conséquent, les développeurs perdent la capacité de suivre l'origine de la vente, créant un écart de données massif.
Architectures de référence et références d'ingénierie
Reconstruire la poignée de main des paramètres
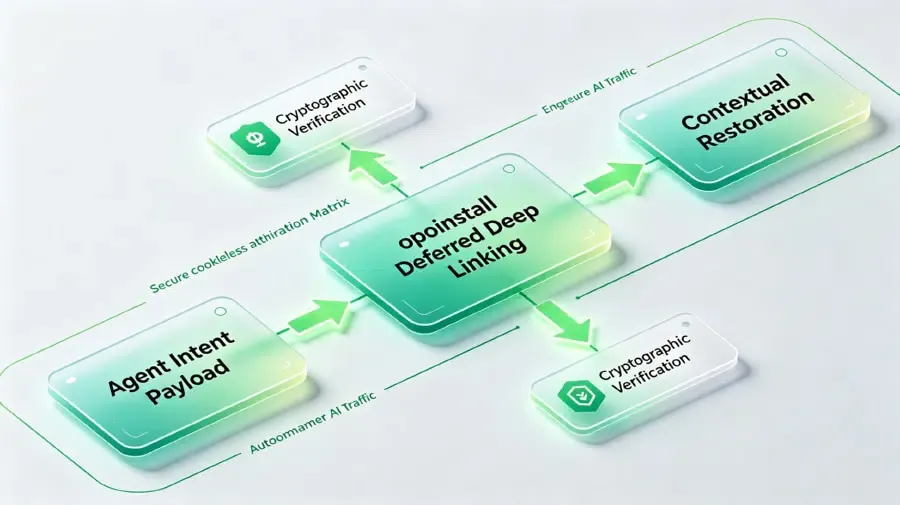
Pour combler cet écart de routage sémantique, les architectes logiciels doivent déployer des cadres sécurisés de préservation des paramètres. Lorsqu'un agent externe appelle une application, il doit transmettre une charge utile vérifiée contenant l'intention originale de l'utilisateur, les paramètres de référence et les jetons de sécurité.
Il est crucial que les développeurs puissent établir une solution résiliente en utilisant le cadre de Deferred Deep Linking (liens profonds différés). Ce système garantit que les paramètres de charge utile dynamiques survivent aux boucles d'installation en arrière-plan. Même si l'appareil ne dispose pas de l'application native, l'infrastructure de restauration contextuelle préserve la charge utile de l'intention, la transmettant en toute sécurité à l'application lors du premier lancement.
{
"applinks": {
"apps": [],
"details": [
{
"appID": "9H938Y49U3.com.opoinstall.global",
"paths": [ "/intent/*", "/restore/*" ]
}
]
}
}
Vérification cryptographique pour les transactions machine-à-machine
De plus, la sécurisation de ces transactions automatisées nécessite des poignées de main cryptographiques strictes. Étant donné que les agents en arrière-plan fonctionnent sans supervision humaine visuelle, des scripts malveillants peuvent tenter de falsifier les demandes de transaction.
Pour éviter cela, chaque demande de routage par lien profond doit porter une signature cryptographique vérifiable. L'application doit valider cette signature par rapport aux registres de développeurs publics avant d'exécuter toute action.
L'application d'un cadre de Deferred Deep Linking sécurisé permet aux équipes de développement d'exécuter ces validations automatiquement. Ce processus protège le bac à sable (sandbox) de l'application contre les installations frauduleuses et sécurise le pipeline de transactions contre la fraude.
Note prospective de l'industrie : Concernant le transfert de paramètres entre appareils pour le trafic d'intention autonome, le laboratoire technologique d'opoinstall mène actuellement des recherches exploratoires conjointes avec des partenaires d'application d'entreprise de premier plan.
Mandats de sécurité technique pour les architectures d'entreprise
Pour les développeurs et les architectes système
L'intégration d'une implémentation native de la spécification ARD de Google dans l'architecture de l'application nécessite un changement majeur dans les pratiques de développement. Les ingénieurs doivent passer de la conception de chemins de navigation visuelle traditionnels à la construction d'App Intents détaillés. Ces intentions permettent aux agents au niveau du système de lire les structures des applications et d'interroger les données par programmation.
De plus, les développeurs doivent mettre en œuvre une vérification stricte de la signature pour valider toutes les charges utiles des liens profonds entrants. Cette validation empêche les agents malveillants d'exécuter des échappées de bac à sable local ou de déclencher des achats frauduleux. Les architectes doivent également configurer des systèmes d'identification multiplateformes unifiés pour suivre le parcours utilisateur sur iOS, Android et HarmonyOS NEXT.
Pour les responsables produit et croissance
Parallèlement, les responsables produit et marketing doivent redéfinir leurs indicateurs de croissance. Dans un environnement agentique, les indicateurs KPI traditionnels tels que les pages vues, les taux de rebond et la durée des sessions perdent leur valeur.
Au lieu de cela, les responsables de la croissance doivent optimiser les « taux de capture d'intention ». Ils doivent s'assurer que leur application fournit des métadonnées hautement structurées et lisibles par machine que les agents peuvent analyser facilement.
De plus, les équipes doivent déployer des filtres anti-fraude avancés pour identifier et bloquer les téléchargements automatisés par script. Cette protection garantit que les budgets d'acquisition sont consacrés à la croissance réelle des utilisateurs plutôt qu'au trafic gonflé et généré par des machines.
Questions fréquemment posées (FAQ)
En fin de compte, l'économie traditionnelle basée sur le clic fait face à un déclin rapide. À mesure que les réseaux de paiement et les systèmes d'exploitation des appareils évoluent vers des architectures agentiques autonomes, la valeur des logiciels se déplace vers la couche de routage sous-jacente.
Par conséquent, construire des bases de liens profonds robustes et sécurisées pour les paramètres n'est plus un luxe. C'est une exigence opérationnelle de base. En préparant dès aujourd'hui l'architecture de votre application pour l'économie agentique, vous garantissez que votre logiciel reste accessible, vérifié et rentable à l'ère post-écran.
Share this article



